

Indexing is understood as adding information about a website to a search engine’s database. A searchable database can be compared to a library catalog containing information about books. Only there are websites instead of books.
Indexing is an integral part of resource promotion work. Only then will all other optimization elements be added. In some situations, it is necessary to prohibit indexing of the site. If the site has problems with indexing, your company will not get customers from the site and will suffer.
What is indexing in search engines?
Simply put, indexing is the process of gathering data about a website. Until the information about the new page is in the database, it will not be displayed at the request of users. This means that no one will see your site.
Let’s see how documents are indexed. A search robot (crawler) browses resources and finds new ones. The data is analyzed: the content is cleaned of unnecessary information and at the same time a list of tokens is formed. A lexeme is a combination of all meanings and grammatical forms of a word in the Russian language.
All the collected data are sorted, the marks are arranged in alphabetical order. At the same time the data is processed, the search engine links the information to specific topics.
An index entry is created. This is the standard process for indexing documents for search engines. Meanwhile, Yandex and Google have a slight disagreement on technical issues. But the general principles are the same.
How to find out the number of indexed pages?
There are several options how to check the indexing of the site in Yandex or Google. Choose the one that is convenient for you.
The first way is to use Yandex.Webmaster and Search Console. In Webmaster, you can use the special tool Check URL Status. Specify the link to the desired page and in a few minutes (in some cases it can be delayed up to several hours) you will find out whether it was included in the index or not.
To check the indexed URLs in Search Console, you need to enter the link in the search bar that appears at the top of the screen. The form will open to see if it is indexed by the search engine.
Another option is the site command. If you do not want to add the resource to the webmasters’ systems, you can simultaneously check all the documents in the index of the search engine. To do this, use a special command: type the search query Yandex or Google site:mysite.ru.
The easiest way to check the indexing of certain documents is to use third-party services for this purpose. Serpstat, Semrush and similar SEO platforms allow you to check indexing of 50 pages in Yandex and Google. Specify the links related to them in a special format (remember http:// or https://) and click the “Start verification” button.
Sometimes the tool takes a long time to get test results from one or two positions, but this does not significantly affect the functionality of the service.
Another service, the RDS Bar plugin for Chrome, Mozilla and Opera, allows you to get detailed information about all the documents opened in the browser, including whether they are indexed or not.
Manage indexing with a robots.txt file
The robots.txt functions offer several options for managing indexing:
-
Clean-param: – Specifies to accept parameters that do not affect the display of the content of the resource (such as UTM tags or ref links).
Example entry: Clean-param: utm /catalog/books.php
-
Sitemap: – Specifies the path to the XML-map, although there can be multiple maps. The directive is also supported by most search engines (including Google).
Example: Sitemap: https://site.ru/sitemap.xml
How to close the site from indexing?
Search engines don’t need to see every URL. For some of them – for example, services, or those that are still under development – it is better not to pay attention to search robots. To prevent such pages from entering the source data, it is better to disable them immediately.
There are several ways to do this:
-
Use the disable command on the Robots.txt file. This file defines the crawler rules: some of its pages can be indexed by certain users, while others are prohibited. If you want to prevent access to the original page data, use the opt-out option. For more information on working with the file, read the Yandex manual.
-
Add the noindex tag to the HTML code of the page. This is probably the easiest way to prevent a robot from indexing a particular page or page type. To use it, simply add the directive to the HTML code section of the page.
-
Use authentication. Some pages, such as Personal Account under development and “Drawings”, may be closed to robots in the authorization form. This is the most reliable way, because even pages that are not indexed in robots.txt or noindex allow them to use search results if they are linked from other pages.
Robots meta tag
You can also block a site or a specific page from being indexed by using the robots meta tag. For crawlers, this tag means high priority, so it works even better.
To avoid scale indexing
Using the meta tag, you can also use one of the robots by specifying the robot name instead of name=”robots”.
For Google search engine:
For Yandex search engine:
Use robots.txt
Typically, a site should be indexed by default, even if you don’t do anything about it. But if you understand the parameters, you will get fast and reliable indexing, and if you have problems, you will quickly understand what the reason is.
The first thing you need to do is create a robots.txt file and use it for indexing. Most content management systems (CMS) have automated solutions for creating them. However, you should still understand what directives are used in this document.
The photo shows an example of bots for WordPress:

And here is an example for a site on Bitrix:

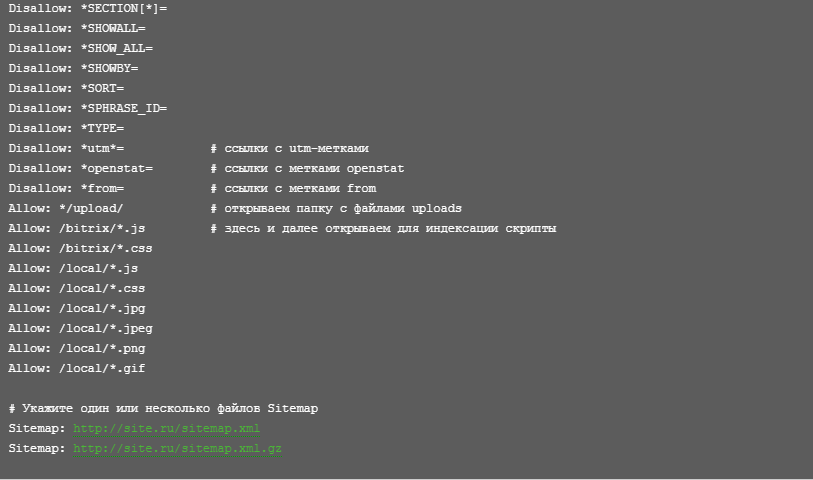
The list below shows the main parameters used in robots.txt:
-
User Agent: Displays the crawler for which the rules are set.
-
Sitemap: Displays the sitemap of the file.
-
Clean-param: Specifies pages where some links should not be considered, such as UTM tags.
-
Access: Allows documents to be indexed.
-
Crawl-delay: Tells the crawler the minimum waiting time between visiting the previous and next pages of the site.
-
User Agent: Indicates that the directives are intended for Yandex. or google.
-
Ban: The site indexing ban directive specifies which pages are not included in the directory. These are technical documents, especially the site admin panel and plugins.
How to open a site for indexing? It is enough to remove the ban rule from robots.
How to speed up site indexing?
The sooner search engines update a page, the sooner visitors can access it. You can reduce your waiting time by following these guidelines:
-
Be sure to add the website to the webmaster panel – Google Search Console and Yandex.Webmaster, set links to the sitemap and robots.txt files.
-
Add new unique content to your site regularly.
-
Don’t forget to link the pages together.
-
Add links to new pages on social networks and other sites.
Indexing issues can be discovered during a site audit. We will not only identify errors, but also give recommendations on their elimination.
If you liked our article and are ready to check the indexing of the site yourself, we are waiting for your feedback in the comments.
Posted by: 04/28/2022
back →
source: Freelance Job


0 Comments
Any Queries , You May Ask